-
/282-large.jpg,q1397111417.pagespeed.ce.FfwQH92h5A.jpg)
Выборы и математика
можно ли на основании статистики надёжно обнаружить фальсификации, если таковые имеются?Теги:
/282-large.jpg,q1397111417.pagespeed.ce.FfwQH92h5A.jpg)
 Vale
Vale

iodaruk> А чё-квантовая теория выборов, островки стибильности... Хуле... ")
Лучше так:
Прекратите клеветать на народ! Пики - это реальные цифры, провалы и плато ниже их - происки Клинтонихи! Вот такое у меня ЧУЙСТВО!
Лучше так:
Прекратите клеветать на народ! Пики - это реальные цифры, провалы и плато ниже их - происки Клинтонихи! Вот такое у меня ЧУЙСТВО!
"Не следуй за большинством на зло, и не решай тяжбы, отступая по большинству от правды" (Исх. 23:2)

 инфо
инфо инструменты
инструменты
russo> НЕЛЬЗЯ. Именно методами стат. анализа. И даже повторный пересчет бюллетеней не уберет подброшенные бюллетени и влияние адмнистративного давления.
Повторный пересчёт убрал бы приписки на уровне грубой подмены итоговых документов, с результатами подсчёта.
А - как утверждали некоторые джентльмены, начиная с Корнея - именно такие наглые замены итоговых сводок и составляют основную массу фальсификаций. И я склонен этому верить.
Да, если бы состоялся повторный пересчёт, в честности к-го можно быть уверенным - материал для сравнения был бы ценный.
Повторный пересчёт убрал бы приписки на уровне грубой подмены итоговых документов, с результатами подсчёта.
А - как утверждали некоторые джентльмены, начиная с Корнея - именно такие наглые замены итоговых сводок и составляют основную массу фальсификаций. И я склонен этому верить.
Да, если бы состоялся повторный пересчёт, в честности к-го можно быть уверенным - материал для сравнения был бы ценный.
Сергей-4030> И "правый всплеск" у ЕР, явно больший 5%, вас не волнует?
Т.е. вы утверждаете, что в одном этом всплеске содержится более 5% от всех поданных голосов?
Подчёркиваю: от ВСЕХ проголосовавших, не только за ЕР, а вообще проголосовавших на выборах.
Сергей-4030> Эти разумные модели должны прежде всего объяснить "правые всплески" и локальные минимумы около "круглых" чисел.
Естественно, зачем говорить банальности?
В разумные модели входят и разумные модели фальсификаций.
ЗыСы Оверквотинг подредактируйте.
Т.е. вы утверждаете, что в одном этом всплеске содержится более 5% от всех поданных голосов?
Подчёркиваю: от ВСЕХ проголосовавших, не только за ЕР, а вообще проголосовавших на выборах.
Сергей-4030> Эти разумные модели должны прежде всего объяснить "правые всплески" и локальные минимумы около "круглых" чисел.
Естественно, зачем говорить банальности?
В разумные модели входят и разумные модели фальсификаций.
ЗыСы Оверквотинг подредактируйте.
Fakir> Вообще, наверное, для сколько-нибудь достоверных оценок величин возможных подделок - только численным моделированием: задаться какими-то разумными моделями, и промонтекарлировать много тыщ раз.
Вот вам исходный материал для моделирования. Один из.
Вот вам исходный материал для моделирования. Один из.

"Не следуй за большинством на зло, и не решай тяжбы, отступая по большинству от правды" (Исх. 23:2)
Сергей-4030> И за ЕР видите?
В комментариях к первоисточнику:
> Maxim Pshenichnikov - Статистика выборов по Москве: двуголовая гидра
Гипотеза более чем сомнительная (не сама по себе - можно же представить две сблокировавшиеся разные партии, которые пошли бы на выборы одним пунктом - а именно для наших реалий). Но.
В комментариях к первоисточнику:
> Maxim Pshenichnikov - Статистика выборов по Москве: двуголовая гидра
Нормальное распределение здесь не применимо. Оно может быть с натяжкой применено к отдельно взятому региону.
Пример один регион поддерживает партию больше 1 другой больше партию 2.
Сумма нормальных распределений с разными центрами уже ненормальное распределение.
Совершенно верно, я полностью согласен. Две фокальные точки в распределнии ЕР (см.след.пост) говорят о наличии в пределах Москвы двух групп, которые демонстрируют совершенно разные электоральные предпочтения.
Гипотеза более чем сомнительная (не сама по себе - можно же представить две сблокировавшиеся разные партии, которые пошли бы на выборы одним пунктом - а именно для наших реалий). Но.
 minchuk
minchuk

Fakir> Гипотеза более чем сомнительная...
Это не "гипотеза", это был сарказм автора. Ты катастрофически теряешь чувство юмора.
Ты катастрофически теряешь чувство юмора. ")
Это не "гипотеза", это был сарказм автора.
Ты катастрофически теряешь чувство юмора.
!"Ваше дело правое, мое дело Львиное..."

А не ты? ")
И неважно, с какой модальностью гипотеза была высказана.
И не так даже важно, представимо ли нечто подобное в нашей сегодняшней ситуации - желательно бы выработать наиболее общий подход. Глядя на имеющиеся цифры, как на какие-нибудь марсианские.
И "вообще" гипотеза, что если бы перед выборами, скажем, ЛПДР объединилась с "Яблоком" в Лдпоблоко или Яблдпр, то новая партия получила бы двугорбое распределение - вполне пригодна к обсуждению, и не является заведомо абсурдной.
Если пробовать притянуть за уши к реальности - ну можно бы и в самом деле подумать, что есть люди, голосующие за ЕР по сильно разным мотивам...
И неважно, с какой модальностью гипотеза была высказана.
И не так даже важно, представимо ли нечто подобное в нашей сегодняшней ситуации - желательно бы выработать наиболее общий подход. Глядя на имеющиеся цифры, как на какие-нибудь марсианские.
И "вообще" гипотеза, что если бы перед выборами, скажем, ЛПДР объединилась с "Яблоком" в Лдпоблоко или Яблдпр, то новая партия получила бы двугорбое распределение - вполне пригодна к обсуждению, и не является заведомо абсурдной.
Если пробовать притянуть за уши к реальности - ну можно бы и в самом деле подумать, что есть люди, голосующие за ЕР по сильно разным мотивам...
Fakir> А не ты?
Ты таки пытался шутить?
Fakir> ...есть люди, голосующие за ЕР по сильно разным мотивам...
Ага, там же: "пик поменьше - это за Медведа, а побольше - за Путена".
Ты таки пытался шутить?
Fakir> ...есть люди, голосующие за ЕР по сильно разным мотивам...
Ага, там же: "пик поменьше - это за Медведа, а побольше - за Путена".
!"Ваше дело правое, мое дело Львиное..."
Зачем? Просто если уж честно рассматривать всё - то надо рассматривать всё, хоть сколько-нибудь разумное.
minchuk> Ага, там же:
Это как раз шутки, которые можно смело скипнуть. Что не отменяет принциипиальной возможности.
Кстати, если бы гипотеза была верна - можно было бы ожидать двухпикового распределения за КПРФ (собственно тех, кто действительно за КПРФ, и тех, кто "лишь бы не за ЕР"). Но как-то не видно.
Т.е. либо эффект не проявляется, либо доля тех, кто "лишь бы не за ЕР" - мала. Второе тоже правдоподобно, т.к. КПРФ набрала не сильно больше, чем в 2007, и 3-5%, размазанных по "второму пику", затерялись бы.
Кстати, зато двугорбый пик есть у "Яблока". Или у них отобрали голоса (причём... не, не соображу сходу, как надо было отбирать, чтобы получить именно такое распределение), или - как раз различная мотивация.
minchuk> Ага, там же:
Это как раз шутки, которые можно смело скипнуть. Что не отменяет принциипиальной возможности.
Кстати, если бы гипотеза была верна - можно было бы ожидать двухпикового распределения за КПРФ (собственно тех, кто действительно за КПРФ, и тех, кто "лишь бы не за ЕР"). Но как-то не видно.
Т.е. либо эффект не проявляется, либо доля тех, кто "лишь бы не за ЕР" - мала. Второе тоже правдоподобно, т.к. КПРФ набрала не сильно больше, чем в 2007, и 3-5%, размазанных по "второму пику", затерялись бы.
Кстати, зато двугорбый пик есть у "Яблока". Или у них отобрали голоса (причём... не, не соображу сходу, как надо было отбирать, чтобы получить именно такое распределение), или - как раз различная мотивация.
Это сообщение редактировалось 10.12.2011 в 20:37
Еще раз поразглядывал этот график:
http://pics.livejournal.com/oude_rus/pic/000tb930/s640x480
- и начинаю приходить в недоумение.
График, напомню, отображает голосование только по Москве.
Но.
Тогда даже если ВСЕ распределения по всем партиям - нормальные, это же по сути означает ту самую неоднородность московских избирателей по участкам, кажущуюся всем такой невероятной. Ведь из графика напрямую следует, к примеру, что есть некое число участков, где ЛДПР имеет 10%, и весьма ненулевое количество - где оно имеет 5% и менее. Есть больше двух сотен участков, где у СР 20% голосов, и более сотни - где лишь около 10%. И так далее. То есть офигительный разброс по участкам внутри одного города!
http://pics.livejournal.com/oude_rus/pic/000tb930/s640x480
Здесь показано количество избирательных участков (УИКов), на которых такая-то партия получила столько-то голосов. Например, КПРФ получила 20% голосов на 226 участках.
- и начинаю приходить в недоумение.
График, напомню, отображает голосование только по Москве.
Но.
Тогда даже если ВСЕ распределения по всем партиям - нормальные, это же по сути означает ту самую неоднородность московских избирателей по участкам, кажущуюся всем такой невероятной. Ведь из графика напрямую следует, к примеру, что есть некое число участков, где ЛДПР имеет 10%, и весьма ненулевое количество - где оно имеет 5% и менее. Есть больше двух сотен участков, где у СР 20% голосов, и более сотни - где лишь около 10%. И так далее. То есть офигительный разброс по участкам внутри одного города!

Сергей-4030> Но, конечно, все равно графики выглядят ужасно и из "общих соображений" понятно, что наверняка выборы подтасованы.
Вопрос "как" пожалуй самый интересный.
При интерпертации их народ почему-то не хочет обращать внимание вот на такие цифры.
// www.politlab.org
Как видно из таблицы, число членов Всероссийской политической партии «Единая Россия» превышает 46% от общего числа членов всех политических партий России, которое составляет 2 723 796 человек. На втором месте, с отставанием в четыре раза, политическая Партия «Справедливая Россия: Родина/Пенсионеры/Жизнь». Третье место делят, почти с равным результатом, КПРФ и АПР. Замыкает список партий, с числом членов более 100 тысяч человек, политическая партия «Либерально-демократическая партия России».
Этим, в том числе и объясняется то, что кривая у ЕР отличается от остальных.
Вот если бы скажем КПРФ/ЕР/ЛДПР/СР имели равную численность, то тогда такая кривая однозначно означала бы подтасовки...
Вопрос "как" пожалуй самый интересный.
При интерпертации их народ почему-то не хочет обращать внимание вот на такие цифры.
POLITECON.COM :: open new political economy community
open new political economy community// www.politlab.org
Как видно из таблицы, число членов Всероссийской политической партии «Единая Россия» превышает 46% от общего числа членов всех политических партий России, которое составляет 2 723 796 человек. На втором месте, с отставанием в четыре раза, политическая Партия «Справедливая Россия: Родина/Пенсионеры/Жизнь». Третье место делят, почти с равным результатом, КПРФ и АПР. Замыкает список партий, с числом членов более 100 тысяч человек, политическая партия «Либерально-демократическая партия России».
Этим, в том числе и объясняется то, что кривая у ЕР отличается от остальных.
Вот если бы скажем КПРФ/ЕР/ЛДПР/СР имели равную численность, то тогда такая кривая однозначно означала бы подтасовки...

Очень интересно. Очень.
Но нет ли критики от социологов?
За этим ЖЖ сейчас стоит следить особенно внимательно. Жду следующих записей.
Автор - вы?
P.S. Да, и определённо стоило запостить не только ссылку, но хотя бы краткие выжимки.
Но нет ли критики от социологов?
За этим ЖЖ сейчас стоит следить особенно внимательно. Жду следующих записей.
Автор - вы?
P.S. Да, и определённо стоило запостить не только ссылку, но хотя бы краткие выжимки.
Fakir> Очень интересно. Очень.
Fakir> Но нет ли критики от социологов?
Сам бы хотел услышать такую критику.
Fakir> За этим ЖЖ сейчас стоит следить особенно внимательно. Жду следующих записей.
Fakir> Автор - вы?
нет, не я.
Fakir> P.S. Да, и определённо стоило запостить не только ссылку, но хотя бы краткие выжимки.
в следующий раз сделаю.
Fakir> Но нет ли критики от социологов?
Сам бы хотел услышать такую критику.
Fakir> За этим ЖЖ сейчас стоит следить особенно внимательно. Жду следующих записей.
Fakir> Автор - вы?
нет, не я.
Fakir> P.S. Да, и определённо стоило запостить не только ссылку, но хотя бы краткие выжимки.
в следующий раз сделаю.
Fakir> Очень интересно. Очень.
Fakir> Но нет ли критики от социологов?
Продолжаю спортивный сёрфинг. Читаю комменты в предыдущей ссылке
letopis.kulichki.net/2011/10-2011/nom2042.htm
Поэтапное построение моделей честных и нечестных выборов с их анализом и демонстрацией слайдов, т.е. графиков распределений для этих моделей.
Fakir> Но нет ли критики от социологов?
Продолжаю спортивный сёрфинг. Читаю комменты в предыдущей ссылке
letopis.kulichki.net/2011/10-2011/nom2042.htm
Поэтапное построение моделей честных и нечестных выборов с их анализом и демонстрацией слайдов, т.е. графиков распределений для этих моделей.
dumendil> По поводу вида распределения.
dumendil> svshift.livejournal.com/108187.html
ИМХО, читать обязательно. И западные исследования по ссылкам. У кого есть ссылки на серьёзную критику (если такие имеются) - очень просим.
Вкратце основные выводы:
Корреляция между явкой и разницей первых двух результатов — это известный факт. Гуглим electoral closeness turnout correlation — отсюда корреляция высокого результата ЕР и высокой явки.
Характреный пик около 100% явки — не наше уникальное явление. Подобное наблюдается в Израиле как раз в арабских общинах.

// svshift.livejournal.com
...Делается феноменальный вывод — мол, там, где явка высокая — за ЕР явно вбрасывали! Этот вывод делается из одного единственного предположения — что "результат ЕР" должен быть статистически независим от "явки". Для того, чтобы такое предположение делать, надо быть очень смелым и очень наивным человеком. А чтобы оценить правомочность такой предпосылки — надо быть не программистом, и не математиком, а, мать вашу, СОЦИОЛОГОМ !!!!
Поэтому, проведу пятиминутку по ликбезу в области электоральной социологии, — слава Гуглу всемогущему, это не трудно.
1. Явкой >90% сегодня никого не удивить — см. тут: Voter turnout - Wikipedia, the free encyclopedia видно, что в странах без обязательной явки высокий процент характерен для стран с однородным этническим составом — "все свои". В Штатах и в Индии явка меньше чем у нас.
2. Сильная корреляция между явкой и территориальными результатами наблюдается !!!СЮРПРИЗ!!! не только у нас.
Прежде всего такая корреляция наблюдается там, где парламенты формируются не пропорционально, как у нас сейчас, а мажоритарно. Если известно, что в округе таком-то лидирует по рейтингам такая-то партия — сторонники оппонентов просто не пойдут — явка снижается, причем, соотвественно, чем выше отрыв лидирующей партии в округе, тем выше явка. Если отрыв не очень сильный — явка вялая — т.к. сторонников проигрывающей стороны много, и большинство из них по-любому не придет. Про это есть ссылка даже в приведенной мною статье на википедии. — т.е. в их случае наблюдается строгая корреляция между вилкой в рейтинге двух лидеров и явкой. При этом, если между двумя лидерами наблюдается почти ничья — тогда явка снова может возрасти — типа народ начинает думать, что его голос решающий.
У нас система пропорциональная, но вывод похожий. Пример: выборы в тайване: при низкой вилке рейтингов (почти ничье) явка неопределенная (зависит от других фаторов), при сильном отрыве лидера в рейтинге - явка всегда высокая.
http://www.accessecon.com/Pubs/EB/2011/Volume31/EB-11-V31-I2-P173.pdf
выборы в бельгии: http://www.diw.de/documents/dokumentenarchiv/17/41524/Paper-165.pdf (кстати - там явка обязательна)
более полное исследование по венгрии: http://www.etd.ceu.hu/2011/simonovits_gabor.pdf
кстати — именно этим объясняется феномен т.н. "авторитарных выборов" — в странах с сильной и популярной в народе авторитарной властью явка на выборы сравнительно высокая, что, как бэ дает повод "голосам со всего мира" повод заявить о "вбросах" и "нарушениях".
другие исследования на тему ищите по запросу "electoral closeness turnout correlation"
Многочисленные исследования корреляции между явкой и социально-культурными условиями я приводить не буду — сами найдете.
PS: я не утверждаю, что вбросов не было — граждане о них сообщают, даже видео какие-то выкладывают. в новостях были сообщения, что кого-то даже сняли с должности и оштрафовали. Я просто говорю, что приводимая статистика не может являться доказательством этих самых вбросов.
PPS: согласно этой теории, если верить статистике, то особо тщательной проверке следует проверить как раз те участки, которые выбиваются из этой закономерности — т.е. там, где при низкой явке особо высокий результат ЕР.
...
Естественно, возникает вопрос, а что делать с "пиком" около 100% (наши кавказские республики) — ведь, кажется, нет на свете мест, где такое отклонение наблюдалось бы. Оказывается есть. вот реальные данные по реальной стране. Израиль. Роль "чечни" тут выполняет социально-этническая группа "арабы". (см. картинку в конце) http://web.econ.ku.dk/epru/... — в этой статье как раз исследуется вопрос о влиянии социокультурных факторов на явку.
dumendil> svshift.livejournal.com/108187.html
ИМХО, читать обязательно. И западные исследования по ссылкам. У кого есть ссылки на серьёзную критику (если такие имеются) - очень просим.
Вкратце основные выводы:
Корреляция между явкой и разницей первых двух результатов — это известный факт. Гуглим electoral closeness turnout correlation — отсюда корреляция высокого результата ЕР и высокой явки.
Характреный пик около 100% явки — не наше уникальное явление. Подобное наблюдается в Израиле как раз в арабских общинах.

Статистика - оружие массовой дезинформации
Цепкие умы давно отметили, что некоторые регионы в России голосуют активнее, чем другие. Явка в большинстве национальных республик намного выше средней по …// svshift.livejournal.com
...Делается феноменальный вывод — мол, там, где явка высокая — за ЕР явно вбрасывали! Этот вывод делается из одного единственного предположения — что "результат ЕР" должен быть статистически независим от "явки". Для того, чтобы такое предположение делать, надо быть очень смелым и очень наивным человеком. А чтобы оценить правомочность такой предпосылки — надо быть не программистом, и не математиком, а, мать вашу, СОЦИОЛОГОМ !!!!
Поэтому, проведу пятиминутку по ликбезу в области электоральной социологии, — слава Гуглу всемогущему, это не трудно.
1. Явкой >90% сегодня никого не удивить — см. тут: Voter turnout - Wikipedia, the free encyclopedia видно, что в странах без обязательной явки высокий процент характерен для стран с однородным этническим составом — "все свои". В Штатах и в Индии явка меньше чем у нас.
2. Сильная корреляция между явкой и территориальными результатами наблюдается !!!СЮРПРИЗ!!! не только у нас.
Прежде всего такая корреляция наблюдается там, где парламенты формируются не пропорционально, как у нас сейчас, а мажоритарно. Если известно, что в округе таком-то лидирует по рейтингам такая-то партия — сторонники оппонентов просто не пойдут — явка снижается, причем, соотвественно, чем выше отрыв лидирующей партии в округе, тем выше явка. Если отрыв не очень сильный — явка вялая — т.к. сторонников проигрывающей стороны много, и большинство из них по-любому не придет. Про это есть ссылка даже в приведенной мною статье на википедии. — т.е. в их случае наблюдается строгая корреляция между вилкой в рейтинге двух лидеров и явкой. При этом, если между двумя лидерами наблюдается почти ничья — тогда явка снова может возрасти — типа народ начинает думать, что его голос решающий.
У нас система пропорциональная, но вывод похожий. Пример: выборы в тайване: при низкой вилке рейтингов (почти ничье) явка неопределенная (зависит от других фаторов), при сильном отрыве лидера в рейтинге - явка всегда высокая.
http://www.accessecon.com/Pubs/EB/2011/Volume31/EB-11-V31-I2-P173.pdf
выборы в бельгии: http://www.diw.de/documents/dokumentenarchiv/17/41524/Paper-165.pdf (кстати - там явка обязательна)
более полное исследование по венгрии: http://www.etd.ceu.hu/2011/simonovits_gabor.pdf
кстати — именно этим объясняется феномен т.н. "авторитарных выборов" — в странах с сильной и популярной в народе авторитарной властью явка на выборы сравнительно высокая, что, как бэ дает повод "голосам со всего мира" повод заявить о "вбросах" и "нарушениях".
другие исследования на тему ищите по запросу "electoral closeness turnout correlation"
Многочисленные исследования корреляции между явкой и социально-культурными условиями я приводить не буду — сами найдете.
PS: я не утверждаю, что вбросов не было — граждане о них сообщают, даже видео какие-то выкладывают. в новостях были сообщения, что кого-то даже сняли с должности и оштрафовали. Я просто говорю, что приводимая статистика не может являться доказательством этих самых вбросов.
PPS: согласно этой теории, если верить статистике, то особо тщательной проверке следует проверить как раз те участки, которые выбиваются из этой закономерности — т.е. там, где при низкой явке особо высокий результат ЕР.
...
Естественно, возникает вопрос, а что делать с "пиком" около 100% (наши кавказские республики) — ведь, кажется, нет на свете мест, где такое отклонение наблюдалось бы. Оказывается есть. вот реальные данные по реальной стране. Израиль. Роль "чечни" тут выполняет социально-этническая группа "арабы". (см. картинку в конце) http://web.econ.ku.dk/epru/... — в этой статье как раз исследуется вопрос о влиянии социокультурных факторов на явку.
Это сообщение редактировалось 10.12.2011 в 23:50
dumendil> По поводу вида распределения.
dumendil> svshift.livejournal.com/108187.html
О "невозможной неоднородности результатов голосования по Москве".

"Как такое может быть, что в Москве соседние районы голосуют совсем по-разному?"
например: Живой Журнал | Блоги | Сообщества | Рейтинги
Здесь все просто. Проклятые совки заселяли Москву крайне неравномерно. Где-то микрорайон от завода (как мой, например), где-то от академии наук, где от таксомоторного парка, где от института, где от министерства обороны, или другого спец. ведомства. Вот социальные группы и голосуют более-менее солидарно. Уверен, что по карте распределения голосов и явки по Москве, можно составить полный рейтинг самих районов. У себя я знаю, где "генеральские дома", где от Кусковского хим.завода, где от завода Электрон, где "социальные", где "кооперативы" и т.д.
Например, жена у себя на участке заметила интересное распределение — когда она пришла к 15.00 к своей мега-тетради, то увидела, что верхние этажи ее дома уже проголосовали, а нижние еще нет. Это из-за особенностей распределения квартир, в ее доме нижние этажи "социальные", там даже приватизированных квартир нет. У нас подобное рапределение практически по-подъездное. есть подъезды бывшего заводского общежития, есть подъезды расселения местной деревни, на месте которой построили район, и т.д.
А самое главное — !!!!!СЕНСАЦИЯ!!!! 10 лет назад было ТОЖЕ САМОЕ, только тогда, почему-то, никто такого кипиша не устраивал по этому поводу:
Причины территориальной неоднородности результатов голосования следует искать в первую очередь в социально-демографических особенностях населения разных районов Москвы. Так, в работах В.А. Колосова и О.И. Вендиной была установлена связь результатов голосования в районах Москвы с возрастным составом электората, с профессиональным составом, а также с типом застройки районов и характером жилого фонда. В частности, отмечалось, что КПРФ получает наибольшую поддержку не в рабочих районах (в отличие от ЛДПР и "Трудовой России"), а в районах со значительной долей пенсионеров, обладавших ранее высоким статусом (из научно-технической интеллигенции, номенклатуры и старшего офицерства). Поддержка "правых" партий высока среди жителей кооперативных домов, а также в престижных районах, население которых пополнилось представителями новой номенклатуры и делового мира. За "партию власти" более охотно голосуют жители ведомственных домов, принадлежащих институтам и предприятиям военно-промышленного комплекса, а также жители новых домов, получившие квартиры бесплатно. Поддержка ЛДПР наиболее высока в районах со значительной долей рабочих низкой квалификации, включая "лимитчиков".
Следует также отметить, что многие районы сильно неоднородны по типу застройки и, соответственно, по своему социальному составу. Поэтому различия в электоральном поведении наблюдаются не только между районами, но и между кварталами и даже отдельными домами внутри районов. В этом случае на уровне района происходит усреднение и нивелировка результатов голосования. В частности, Колосов отмечает существенную неоднородность таких районов, как Измайлово, Новогиреево, Перово и Ясенево.
Проблема различий в электоральном поведении москвичей и их связи с социально-демографическими факторами требует дальнейшего изучения.
Взято из:
 Карта Москвы, иллюстрирующая классификацию районов по политическим предпочтениям. Голубым цветом обозначены "нейтральные" районы, желтым – "центристские", зеленым – "правые", красным – "левые", малиновым – право–левые".
Карта Москвы, иллюстрирующая классификацию районов по политическим предпочтениям. Голубым цветом обозначены "нейтральные" районы, желтым – "центристские", зеленым – "правые", красным – "левые", малиновым – право–левые".
Как видим, районы разной "политической направленности" очень даже граничили и десять лет назад.
dumendil> svshift.livejournal.com/108187.html
О "невозможной неоднородности результатов голосования по Москве".
Результат
в очередной раз убеждаюсь в том, что единственный глобальный заговор на земле, это Заговор Мировой Глупости. Читаю весь этот электоральный срач в этих ваших… // svshift.livejournal.com"Как такое может быть, что в Москве соседние районы голосуют совсем по-разному?"
например: Живой Журнал | Блоги | Сообщества | Рейтинги
Здесь все просто. Проклятые совки заселяли Москву крайне неравномерно. Где-то микрорайон от завода (как мой, например), где-то от академии наук, где от таксомоторного парка, где от института, где от министерства обороны, или другого спец. ведомства. Вот социальные группы и голосуют более-менее солидарно. Уверен, что по карте распределения голосов и явки по Москве, можно составить полный рейтинг самих районов. У себя я знаю, где "генеральские дома", где от Кусковского хим.завода, где от завода Электрон, где "социальные", где "кооперативы" и т.д.
Например, жена у себя на участке заметила интересное распределение — когда она пришла к 15.00 к своей мега-тетради, то увидела, что верхние этажи ее дома уже проголосовали, а нижние еще нет. Это из-за особенностей распределения квартир, в ее доме нижние этажи "социальные", там даже приватизированных квартир нет. У нас подобное рапределение практически по-подъездное. есть подъезды бывшего заводского общежития, есть подъезды расселения местной деревни, на месте которой построили район, и т.д.
А самое главное — !!!!!СЕНСАЦИЯ!!!! 10 лет назад было ТОЖЕ САМОЕ, только тогда, почему-то, никто такого кипиша не устраивал по этому поводу:
Причины территориальной неоднородности результатов голосования следует искать в первую очередь в социально-демографических особенностях населения разных районов Москвы. Так, в работах В.А. Колосова и О.И. Вендиной была установлена связь результатов голосования в районах Москвы с возрастным составом электората, с профессиональным составом, а также с типом застройки районов и характером жилого фонда. В частности, отмечалось, что КПРФ получает наибольшую поддержку не в рабочих районах (в отличие от ЛДПР и "Трудовой России"), а в районах со значительной долей пенсионеров, обладавших ранее высоким статусом (из научно-технической интеллигенции, номенклатуры и старшего офицерства). Поддержка "правых" партий высока среди жителей кооперативных домов, а также в престижных районах, население которых пополнилось представителями новой номенклатуры и делового мира. За "партию власти" более охотно голосуют жители ведомственных домов, принадлежащих институтам и предприятиям военно-промышленного комплекса, а также жители новых домов, получившие квартиры бесплатно. Поддержка ЛДПР наиболее высока в районах со значительной долей рабочих низкой квалификации, включая "лимитчиков".
Следует также отметить, что многие районы сильно неоднородны по типу застройки и, соответственно, по своему социальному составу. Поэтому различия в электоральном поведении наблюдаются не только между районами, но и между кварталами и даже отдельными домами внутри районов. В этом случае на уровне района происходит усреднение и нивелировка результатов голосования. В частности, Колосов отмечает существенную неоднородность таких районов, как Измайлово, Новогиреево, Перово и Ясенево.
Проблема различий в электоральном поведении москвичей и их связи с социально-демографическими факторами требует дальнейшего изучения.
Взято из:
ch16-3
Выборы в Москве: опыт двенадцати лет. 1989–2000 16.3. Географическая неоднородность результатов голосования в Москве Как было показано в предыдущих главах, степень географической неоднородности электората в Москве не слишком высока. Тем не менее существует заметный разброс в результатах голосования по районам, и этот разброс имеет закономерности, в основном сохраняющиеся от выборов к выборам На географическую неоднородность электората Москвы обратили внимание еще А.В. Березкин и Л.В. Смирнягин, анализируя результаты голосования на выборах народного депутата СССР по Московскому городскому национально-территориальному округу № 1 в 1989 г. // Дальше — lyubarev.narod.ru
Как видим, районы разной "политической направленности" очень даже граничили и десять лет назад.
Это сообщение редактировалось 10.12.2011 в 23:51
jemmybutton.livejournal.com/1359.html
Гипотеза о причинах возникновения пиков на "красивых" числах с графиками по произвольному массиву случайных чисел. Идея: общие делители.
Откуда могут браться пики на «круглых» цифрах
Пока не придумал как это доходчиво объяснить, поэтому просто приведу картинки (если коротко, то это вроде как связано с делимостью на простые числа и тем, что их соотношения дают пики на целых долях всего диапазона, как флажолеты на струне, к примеру).
+UPD: Можно объяснить так: из набора случайных целых чисел, принимающих значение от нуля до n, случайно сочетаемых в обыкновенной дроби, больше способов получить, скажем, ровно 1/7, 1/2 или 3/4, чем, например, 11/70, 201/400 или 61/80
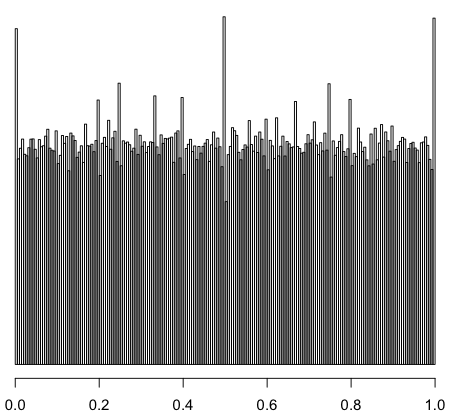
это распределение для отношения двух равномерно распределенных целых случайных величин x и y.
x — от одного до 800 (чуть больше среднего участка), y — произвольная доля от x (округленное до целого).
> sample(800, 1000000, replace = TRUE) -> x$x
> sample(10000, 100000, replace = TRUE)/10000 -> x$y
> x$y <- round(x$x*x$y)
> hist(x$y/x$x, breaks = 200)
если убрать «участки» с x<100 пики уменьшаются, но не пропадают.
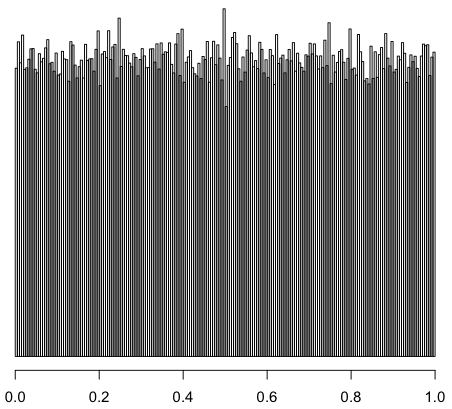
если ограничить значения y (в данном случае y < 1/2x, что ближе к реальности), пики становятся сильно более выраженными (шкала внизу до 0,5, обращаю внимание)

так-то
UPD: та же модель, только для распределения, похожего на настоящее
итак, вот распределение сгенерированных случайных чисел, имитирующих распределение явившихся на выборы людей:
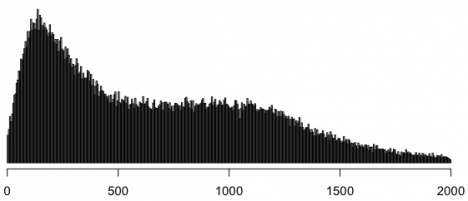
вот распределение, имитирующее распределение голосов за ер (сглаженное, без пиков, здесь и далее шаг в 0,2%):
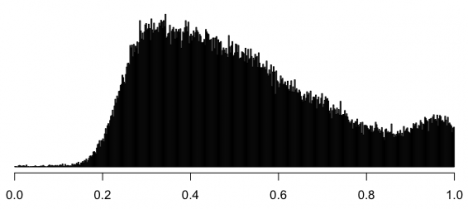
далее я помножил «явившихся» из распределения сверху на «голоса» из распределения снизу, округлил до целых чисел и снова поделил на «явившихся» (можно было просто сымитировать распределение голосов за ер, но я что-то не подумал об этом). вот что из этого получилось:
404 Not Found [not image]
по-мойму так красота.
UPD: проверка на настоящих данных
Для проверки я добавил случайный шум с амплитудой в 1 голос к числу проголосовавших и к голосам за ер.
до:

после:
более или менее очевидную фигню мне видно только на 75 и 85.
Пики не пропадают, если отбросить маленькие участки (кое-кто считает это аргументом против чисто стохастических объяснений), потому, что имеет значение не размер участка, а количество участков относительно их размера.
А это я облажался и другую картинку повесил, но она тоже не интересная, это, похоже, артефакт, вызванный тем, что выдается на участок круглое число бюллетеней.
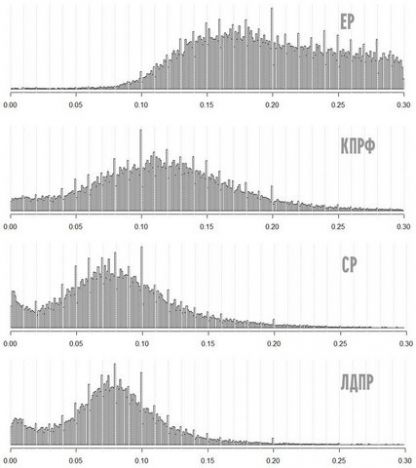
Количество участков от (голосов за партию / число избирательных бюллетеней, полученных участковой избирательной комиссией). Если исключить участки <100 чел., картина почти не меняется, если <500, пики на каждом проценте остаются.
Гипотеза о причинах возникновения пиков на "красивых" числах с графиками по произвольному массиву случайных чисел. Идея: общие делители.
Откуда могут браться пики на «круглых» цифрах
Пока не придумал как это доходчиво объяснить, поэтому просто приведу картинки (если коротко, то это вроде как связано с делимостью на простые числа и тем, что их соотношения дают пики на целых долях всего диапазона, как флажолеты на струне, к примеру).
+UPD: Можно объяснить так: из набора случайных целых чисел, принимающих значение от нуля до n, случайно сочетаемых в обыкновенной дроби, больше способов получить, скажем, ровно 1/7, 1/2 или 3/4, чем, например, 11/70, 201/400 или 61/80

это распределение для отношения двух равномерно распределенных целых случайных величин x и y.
x — от одного до 800 (чуть больше среднего участка), y — произвольная доля от x (округленное до целого).
> sample(800, 1000000, replace = TRUE) -> x$x
> sample(10000, 100000, replace = TRUE)/10000 -> x$y
> x$y <- round(x$x*x$y)
> hist(x$y/x$x, breaks = 200)
если убрать «участки» с x<100 пики уменьшаются, но не пропадают.

если ограничить значения y (в данном случае y < 1/2x, что ближе к реальности), пики становятся сильно более выраженными (шкала внизу до 0,5, обращаю внимание)

так-то
UPD: та же модель, только для распределения, похожего на настоящее
итак, вот распределение сгенерированных случайных чисел, имитирующих распределение явившихся на выборы людей:

вот распределение, имитирующее распределение голосов за ер (сглаженное, без пиков, здесь и далее шаг в 0,2%):

далее я помножил «явившихся» из распределения сверху на «голоса» из распределения снизу, округлил до целых чисел и снова поделил на «явившихся» (можно было просто сымитировать распределение голосов за ер, но я что-то не подумал об этом). вот что из этого получилось:
404 Not Found [not image]
по-мойму так красота.
UPD: проверка на настоящих данных
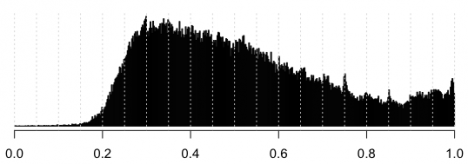
Для проверки я добавил случайный шум с амплитудой в 1 голос к числу проголосовавших и к голосам за ер.
до:

после:

более или менее очевидную фигню мне видно только на 75 и 85.
Пики не пропадают, если отбросить маленькие участки (кое-кто считает это аргументом против чисто стохастических объяснений), потому, что имеет значение не размер участка, а количество участков относительно их размера.
А это я облажался и другую картинку повесил, но она тоже не интересная, это, похоже, артефакт, вызванный тем, что выдается на участок круглое число бюллетеней.

Количество участков от (голосов за партию / число избирательных бюллетеней, полученных участковой избирательной комиссией). Если исключить участки <100 чел., картина почти не меняется, если <500, пики на каждом проценте остаются.
Это сообщение редактировалось 11.12.2011 в 00:08
Из комментариев:
saccovanzetti
проблема с большинством колоколообразных графиков, насколько я понимаю - что там кол-во УИК и/или явка не отнормировано на кол-во избирателей в УИК. почему на таком графике даже при честных выборах должен быть гаусс - мне непонятно. я посмотрел статьи по западным ссылкам - очень-очень бедная база, похоже этой математикой мало кто занимается в мире, что удивительно при таком изобилии кафедр политологии.
a_shen
Cамо по себе ожидание гауссова распределения ни из чего так уж прямо не следует - мало ли что - но если в России похожее на гауссово распределение на прежних сменилось странным распределением с пиками на круглых числах, то "бремя объяснения" этого обстоятельства лежит на защитниках гипотезы честности выборов, по-моему - и это скорее опирается на здравый смысл, чем на какие-то математические теоремы...
...
saccovanzetti
я же говорю - экономически. им не надо между собой сговариваться, если центр координирует экономическую политику на местах и политинформации по зомбоящику. их поведение будет коррелированым (т.н. "вертикаль власти" - не слышали?). если бы марионетки в театре пели случайным образом - вышла бы какафония, гауссианского типа(?). А так "Марсельеза" или "Боже царя храни" получается, в зависимости от того кто дергает за ниточки. фальсификации голосования не являются необходимыми для наблюдаемых отклонений, достаточно вдолбить людям в голову, что только ЕР может их спасти от всех стихийных бед. И что ЕР - не причина этих их бед. Тогда чем хуже их положение (экономическое, например) - тем охотнее они пойдут голосовать, и тем больше будут давать ЕР.
P.S. это как пример. варианты зомбирования более-не-менее преуспевающих в пользу ЕР тоже имеются в достатке (другой мессидж - ЕР причина их экономическог процветания). Которое у них злые коммунисты отнимут, поэтому срочно все бежим и голосуем.
Ivan Operchuk
А так же разное среднее и дисперсия в разных регионах уже нарушают общий гаусс
svshift
у наших голосующих есть родственники, друзья, коллеги, и мнения "за кого пойдешь" озвучиваются заранее.
вот по финляндии, например, статистика показывает "нормальное" распределение по результатам и по явке — это показатель атомизирванности общества. в отличие, например, от италии.
а кое-где есть даже роды, кланы, племена и т.д.
jemmybutton
наличие корреляции между голосами за какую-нибудь партию и явкой бывает и в «нормальных» странах. например вот, на выборах в бундестаг 2002, с ростом явки становится больше голосов за ХДС+ХСС и меньше за остальных. т. е. в принципе, я, конечно, думаю что христианскиедемократы воровали голоса у насчастных левых, но, боюсь, многие со мной не согласятся.
тут вот картинку повесил про это дело jemmybutton - чисто посмеяться
a_shen
задача количественной оценки размера фальсификаций (условно говоря, 5% это или 20%) сложная, и предлагаемые методы требуют разносторонней экспериментальной проверки; сейчас даже появились новые материалы, на основании которых её можно попробовать сделать (выборка наблюдаемых участков), но всё равно это будет спорно.
Поэтому, скажем, требование скорректировать состав госдумы в соответствии с этими статистическими оценками кажется мне нелепым, а вот желание провести выборы "по-нормальному", без чуровых и путинов a priori, мне представляется вполне законным.
svshift
Делается банальное предположение, которое говорит о том, что если пришли 10 человек 100 или 1000, то пропорции за ту или иную партию будут примерно одинаковы.
я русским языком, со ссылками на англоязычные статьи показываю, что это предположение не верно.
умные люди (т.е. не я) в этих статьях говорят, что есть строгая корреляция между разницей результатов (или рейтингов) N1 и N2 и явкой. причем они это доказывают математически, и там же показывают, что результатов корреляции для других кандидатов (т.е. N2,N3,N4 т.д.) нету.
очень просто. гипотезу "результат ЕР статистически не зависит от явки" может принимать или непринимать только специалист в предметной области, т.е. социолог, а не я и не вы.
я просто взял на себя труд посмотреть, работает ли эта гипотеза в других выборах по социологии. ссылки на литературу, которые мне попадались, говорят, что эта гипотеза неверна, и корелляция есть, и сильная.
...
т.е. когда в Венгрии отрыв лидера от N2 кореллирует с явкой — это "демократия", а у нас — "нано-полит-технологии" ?
...
чем выше рейтинг лидера - тем ниже доля сторонников оппонентов. при паритете цена голоса выше. при невысоком преимуществе - цена голоса оппонентов снижается - они забивают, явка падает. при высоком рейтинге лидера - доля оппонентов падает — т.о. общая явка растет. получается - загогулина
работ по корреляции отрыва рейтинга лидера и явки много — в разных странах свои особенности. при невыраженном лидерстве сильнее работают другие параметры (удовлетворенность, усталость, т.д.)
saccovanzetti
проблема с большинством колоколообразных графиков, насколько я понимаю - что там кол-во УИК и/или явка не отнормировано на кол-во избирателей в УИК. почему на таком графике даже при честных выборах должен быть гаусс - мне непонятно. я посмотрел статьи по западным ссылкам - очень-очень бедная база, похоже этой математикой мало кто занимается в мире, что удивительно при таком изобилии кафедр политологии.
a_shen
Cамо по себе ожидание гауссова распределения ни из чего так уж прямо не следует - мало ли что - но если в России похожее на гауссово распределение на прежних сменилось странным распределением с пиками на круглых числах, то "бремя объяснения" этого обстоятельства лежит на защитниках гипотезы честности выборов, по-моему - и это скорее опирается на здравый смысл, чем на какие-то математические теоремы...
...
saccovanzetti
я же говорю - экономически. им не надо между собой сговариваться, если центр координирует экономическую политику на местах и политинформации по зомбоящику. их поведение будет коррелированым (т.н. "вертикаль власти" - не слышали?). если бы марионетки в театре пели случайным образом - вышла бы какафония, гауссианского типа(?). А так "Марсельеза" или "Боже царя храни" получается, в зависимости от того кто дергает за ниточки. фальсификации голосования не являются необходимыми для наблюдаемых отклонений, достаточно вдолбить людям в голову, что только ЕР может их спасти от всех стихийных бед. И что ЕР - не причина этих их бед. Тогда чем хуже их положение (экономическое, например) - тем охотнее они пойдут голосовать, и тем больше будут давать ЕР.
P.S. это как пример. варианты зомбирования более-не-менее преуспевающих в пользу ЕР тоже имеются в достатке (другой мессидж - ЕР причина их экономическог процветания). Которое у них злые коммунисты отнимут, поэтому срочно все бежим и голосуем.
Ivan Operchuk
А так же разное среднее и дисперсия в разных регионах уже нарушают общий гаусс
svshift
у наших голосующих есть родственники, друзья, коллеги, и мнения "за кого пойдешь" озвучиваются заранее.
вот по финляндии, например, статистика показывает "нормальное" распределение по результатам и по явке — это показатель атомизирванности общества. в отличие, например, от италии.
а кое-где есть даже роды, кланы, племена и т.д.
jemmybutton
наличие корреляции между голосами за какую-нибудь партию и явкой бывает и в «нормальных» странах. например вот, на выборах в бундестаг 2002, с ростом явки становится больше голосов за ХДС+ХСС и меньше за остальных. т. е. в принципе, я, конечно, думаю что христианскиедемократы воровали голоса у насчастных левых, но, боюсь, многие со мной не согласятся.
тут вот картинку повесил про это дело jemmybutton - чисто посмеяться
a_shen
задача количественной оценки размера фальсификаций (условно говоря, 5% это или 20%) сложная, и предлагаемые методы требуют разносторонней экспериментальной проверки; сейчас даже появились новые материалы, на основании которых её можно попробовать сделать (выборка наблюдаемых участков), но всё равно это будет спорно.
Поэтому, скажем, требование скорректировать состав госдумы в соответствии с этими статистическими оценками кажется мне нелепым, а вот желание провести выборы "по-нормальному", без чуровых и путинов a priori, мне представляется вполне законным.
svshift
Делается банальное предположение, которое говорит о том, что если пришли 10 человек 100 или 1000, то пропорции за ту или иную партию будут примерно одинаковы.
я русским языком, со ссылками на англоязычные статьи показываю, что это предположение не верно.
умные люди (т.е. не я) в этих статьях говорят, что есть строгая корреляция между разницей результатов (или рейтингов) N1 и N2 и явкой. причем они это доказывают математически, и там же показывают, что результатов корреляции для других кандидатов (т.е. N2,N3,N4 т.д.) нету.
очень просто. гипотезу "результат ЕР статистически не зависит от явки" может принимать или непринимать только специалист в предметной области, т.е. социолог, а не я и не вы.
я просто взял на себя труд посмотреть, работает ли эта гипотеза в других выборах по социологии. ссылки на литературу, которые мне попадались, говорят, что эта гипотеза неверна, и корелляция есть, и сильная.
...
т.е. когда в Венгрии отрыв лидера от N2 кореллирует с явкой — это "демократия", а у нас — "нано-полит-технологии" ?
...
чем выше рейтинг лидера - тем ниже доля сторонников оппонентов. при паритете цена голоса выше. при невысоком преимуществе - цена голоса оппонентов снижается - они забивают, явка падает. при высоком рейтинге лидера - доля оппонентов падает — т.о. общая явка растет. получается - загогулина
работ по корреляции отрыва рейтинга лидера и явки много — в разных странах свои особенности. при невыраженном лидерстве сильнее работают другие параметры (удовлетворенность, усталость, т.д.)
 Serg Ivanov
Serg Ivanov

dumendil> По поводу вида распределения.
dumendil> svshift.livejournal.com/108187.html
Ну вот это я и имел в виду два дня назад. Надеюсь хоть теперь дойдёт
пс.
Существуют три вида лжи: ложь, наглая ложь и статистика, англ. There are three kinds of lies: lies, damned lies, and statistics)
dumendil> svshift.livejournal.com/108187.html
Ну вот это я и имел в виду два дня назад. Надеюсь хоть теперь дойдёт
пс.
Существуют три вида лжи: ложь, наглая ложь и статистика, англ. There are three kinds of lies: lies, damned lies, and statistics)
Прикреплённые файлы:


Это сообщение редактировалось 11.12.2011 в 00:24
dumendil> Гипотеза о причинах возникновения пиков на "красивых" числах с графиками по произвольному массиву случайных чисел. Идея: общие делители.
Я её, честно говоря, не понял.
Я её, честно говоря, не понял.
dumendil>> Гипотеза о причинах возникновения пиков на "красивых" числах с графиками по произвольному массиву случайных чисел. Идея: общие делители.
Fakir> Я её, честно говоря, не понял.
Ну там идея такая. Допустим у нас есть много участков со случайным количеством пришедших голосовать от 0 до 800. Распределение равномерное. И на этих участках за ЕР проголосовало случайный процент. Распределение тоже равномерное. Тпереь построим график разделив количество проголосовавших за ЕР на общее количество пришедших на этот участок. На графике обнаружатся красивые пики на кратных значениях потому что получить отношение 1/5 (у нас же по оси х именно отношение) можно многими способами (2/10, 3/15, 4/20 и т.д. всего 160 отсчётов), а вот 11/73 - способов гораздо меньше (22/146, 33/219 - в заданном диапазоне всего 10 отсчётов). А всё, что кратно 1/5 (или 11/73) на гистограме лягут в один столбик. Будет пик.
Как-то так.
Fakir> Я её, честно говоря, не понял.
Ну там идея такая. Допустим у нас есть много участков со случайным количеством пришедших голосовать от 0 до 800. Распределение равномерное. И на этих участках за ЕР проголосовало случайный процент. Распределение тоже равномерное. Тпереь построим график разделив количество проголосовавших за ЕР на общее количество пришедших на этот участок. На графике обнаружатся красивые пики на кратных значениях потому что получить отношение 1/5 (у нас же по оси х именно отношение) можно многими способами (2/10, 3/15, 4/20 и т.д. всего 160 отсчётов), а вот 11/73 - способов гораздо меньше (22/146, 33/219 - в заданном диапазоне всего 10 отсчётов). А всё, что кратно 1/5 (или 11/73) на гистограме лягут в один столбик. Будет пик.
Как-то так.
Это сообщение редактировалось 11.12.2011 в 01:51

Fakir> Сильная корреляция между явкой и территориальными результатами наблюдается !!!
У нас такое произошло на выборах мэра (только с противоположным знаком)
То ли предвыборная истерика альтернативного кандидата в стиле "все уже решено, будут мега-фальсификации и т.д." сделала свое дело; то ли уверенность что результаты работы действующего мэра говорят сами за себя и найдется мало сторонников, клюнувших на популистские обещания альтернативной стороны, в общем, пожалуй большинство было абсолютно уверено в железобетонной победе "текущего" городского главы... и люди, склоняшиеся в его сторону на выборы особо не пошли (мол, и так ясно...) Ага
С результата офигели все - и избиратели, и выбираемые
У нас такое произошло на выборах мэра (только с противоположным знаком)
То ли предвыборная истерика альтернативного кандидата в стиле "все уже решено, будут мега-фальсификации и т.д." сделала свое дело; то ли уверенность что результаты работы действующего мэра говорят сами за себя и найдется мало сторонников, клюнувших на популистские обещания альтернативной стороны, в общем, пожалуй большинство было абсолютно уверено в железобетонной победе "текущего" городского главы... и люди, склоняшиеся в его сторону на выборы особо не пошли (мол, и так ясно...) Ага
С результата офигели все - и избиратели, и выбираемые
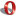
 Сергей-4030
Сергей-4030

dumendil> Ну там идея такая.
Чушь это.
Чушь это.
 TEvg
TEvg
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Исчо раз. Избиратель Петя голосует независимо от избирателя Васи. Поэтому не должно быть зависимости постановки Петей галочки напротив п.6 от явки или неявки Васи на выборы.
Неоднородность избирателей (тоже весьма спорная штука) могла привести к расширению колокола, появлению локальных горбов, но кривулька или её огибающая всё равно должна быть гауссоподобной. Т.е. у неё должен быть правый склон в области больших явок. 100% явка имеет околонулевую вероятность, при свободном волеизъявлении граждан. На 100% редко являются даже 100-200 человек пассажиров на самолет или поезд, которые не только собирались добровольно ехать, но и оплатили за проезд собственное бабло. Многочисленные 100% явки на участки в 1000 чел и больше, притом что выборы многим вообще не усрались, - это насильственное принуждение, либо альтернативная математика.
Извиняйте, я слишком хорошо учил математику, два раза занимал третье и первое место соответсвенно на олимпиаде по городу. На отлично учился в универе. Так что в естественности кривульки ЕР, на фоне прочих кривулек, убеждайте кого-нить другого.
Про ментальность чеченов замечу только, что при полном единодушии туземцев (>99%;>99%), там по участку зачем-то разгуливают люди с автоматами и гранатометами. Я не вижу смысла в их наличии, в условиях, когда все довольны, все голосуют ЗА.
ЗЫ зажигательный ролик за партию А привел бы к расширению/сдвигу колокола, а не к той порнухе, которую мы наблюдаем.

Copyright © Balancer 1997..2018
Создано 05.12.2011
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
Создано 05.12.2011
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
-
 1935: Открытие московского метро (83 года).
1935: Открытие московского метро (83 года).
- Поиск
- Поддержка
-
Поддержи форум! 
- Настройки
- Твиттер сайта Твиты пользователя @AirbaseRu
- Статистика
-
